用扫描仪扫描的文字图像,不能对个别文字进行编辑修改,在教学中,需要利用文字识别软件,将文字图像进行识别,将图像格式转化成文本格式,常见的文字识别软件有很多,主要功能基本相同,尚书七号就是其中很优秀的一款。用尚书七号对文字图像识别转化的过程,利用其主菜单:“文件”、“编辑”、“识别”、“输出”可以很方便地完成。具体步骤为:
步骤1:获取文字图像文件
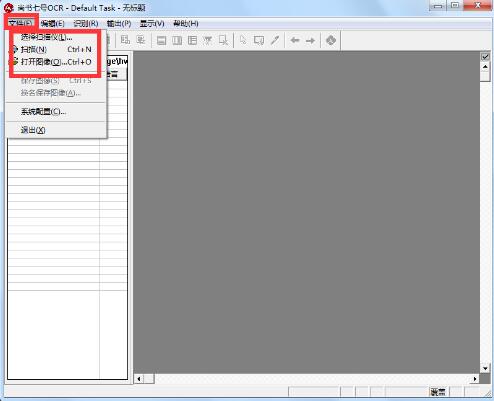
选择“文件”菜单下的“扫描”或“打开图像”(将已经扫描好的图像文件打开)命令,打开图像文件。如果连接了多台扫描仪,可以选择“文件”菜单下的“选择扫描仪”命令,调用扫描仪。
步骤2:对扫描的图像页进行调整
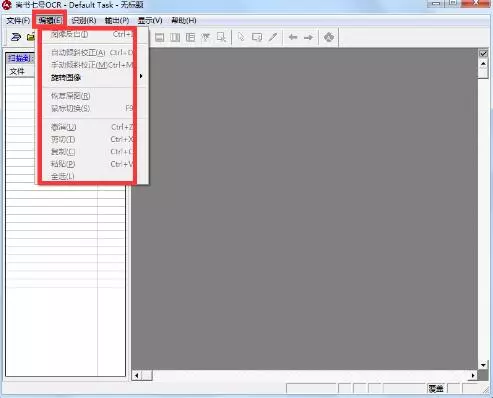
选择“编辑”菜单下“图像页面的处理”子菜单下的“图像页的倾斜校正”(提供自动和手动实现方法)及“旋转”等命令,将扫描的图像页进行调整。
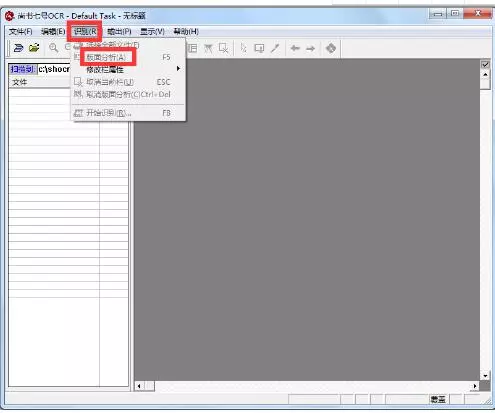
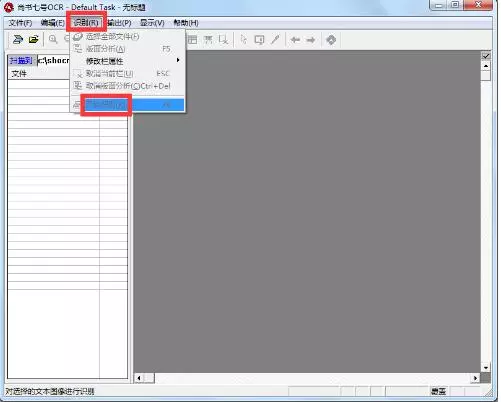
步骤3:版面分析与文字识别转化
版面分析,选择识别范围,在进行文字识别前要选择识别范围,识别过程的核心是“版面分析”。
尚书七号的自动版面分析功能很强,对报纸杂志等复杂的版面,也能保持很高的分析正确率。
设置好后,直接点击“开始识别”的按钮就可以进行文字识别了。
步骤4:校对修改
自动识别完毕,识别结果的“文本窗口”会弹出,这个窗口能够提供识别结果的校对,为了校对方便,尚书七号增加了光标跟随显示原图像行的校对方法(如图3出现的黄色提示行的出现)。
提供的校对方法,一眼就能够看到图像原文和识别出文本的差别,如果发现识别有误,可以进行修改。
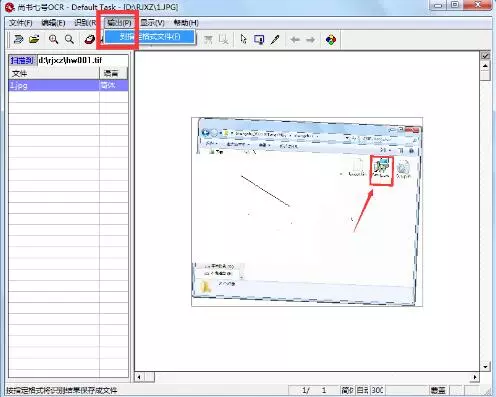
步骤5:输出
如果检查修改后确认无误,选择识别结果的“输出”菜单,输出的文件格式有:RTF、HTML、XLS、22238,可以根据自己的需要选择对应的格式。如果用户想得到类似原文的识别结果,请选择RTF格式。把RTF格式输出的文件用WORD打开后,会发现几乎保留了原文的所有痕迹,包括原来页面中的彩色图像,都已经保留在WORD中了。
1、识别字符
简体字符集:国标GB2312-80的全部一、二级汉字6800多个。2、纯英文字符集。
简繁字集:除了简体汉字外,还可以混识台湾繁体字5400多个以及香港繁体字和GBK汉字。
3、识别字体种类
能识别宋体、仿宋、楷、黑、魏碑、隶书、圆体、行楷等一百多种字体,并支持多种字体混排。
4、识别字号
初号 小六号字体。
5、表格识别可以自动判断、拆分、识别和还原各种通用型印刷体表格。
识别字符简体字符集:国标GB2312-80的全部一、二级汉字6800多个。
简繁字集:除了简体汉字外,还可以混识台湾繁体字5400多个以及香港繁体字和GBK汉字。
识别字体种类能识别宋体、仿宋、楷、黑、魏碑、隶书、圆体、行楷等一百多种字体,并支持多种字体混排。
识别字号初号 小六号字体。
表格识别可以自动判断、拆分、识别和还原各种通用型印刷体表格。
可支持繁体WINDOWS系统
常见问题
1、尚书7号ocr文字识别系统中出现绿色的框是怎么回事?
“可以把扫描上的文字直接用于编辑”与扫描仪无关,什么扫描仪都可以。能“直接用于编辑”属于汉字识别,是靠OCR(光学字符识别)软件实现的。2、尚书七号ocr破解版怎么提取文字?
你只需要在打开的文档中用鼠标选中你想提取的目标文字,然后修改识别框的属性,即——横排、竖排、表格、图片这四种。然后识别就可以了。最后选择输出就可以了。
①扫描设置不当,扫描图像时的扫描分辨率(Resolution)一般应设为300dpi,如果文档字体较小则需要将扫描分辨率设定为更高值如400dpi或600dpi。缩放比例(Scaling)设为100%,亮度阀值(Threshold、Brightness)需根据纸张和印刷的质量调节,避免扫描图像过黑或过淡 。
②如自动版面分析有错误,这时请用户用鼠标自己划分出正确的版面块;版面块的版式设置错误,如将横版的设置为竖版,竖版的设置为横版等,这时请用户自行将块的版式修改正确。
③原稿印刷质量太差,笔画断裂严重、油墨太浓、字与字之间粘连严重等也可能使识别率显著降低。④识别语言选项选择不当,应根据原稿正确选择“简体”、“简繁”或“英文”

Auslogics Registry Cleaner
系统工具
失易得数据恢复
系统工具
Starus FAT Recovery
系统工具
Edgeless
系统工具
x3eelwln.dll文件电脑版
系统工具
VSFilterMod.dll文件电脑版
系统工具
快易安卓恢复官方版
系统工具
fences破解版 中文汉化版
系统工具
qgif.dll文件
系统工具
COS操作系统操作官方版v1.0免费下载
系统工具
HttpClient.jar免费版v1.4下载
系统工具
xvidcore.dll文件官方版v1.0下载
系统工具













